

ZK Proofs: Is Privacy Cheap Enough to Be Mainstream?

Zero Knowledge (ZK), as the name suggests, is like a magic trick to prove that a claim is true without revealing the underlying information itself. You do not need the absolute knowledge of that information to verify that it existed.
In 1985, when ZK was first introduced, it answered the question: “Can a prover convince a verifier that a statement is true without revealing the witness?”
This question paved the way for the development we have today. From 1985 to the 2010s, ZK was a research topic in cryptography.
In 2013, blockchains provided ZK with a practical, mass-market rationale for existence: privacy for public ledgers and scalability by proving correctness without replaying computations.
Early proposals, such as Zerocoin and later work, such as Zerocash, demonstrated how to prove ownership and validity without exposing identities or balances.
Zcash shipped that idea into a live network in 2016.
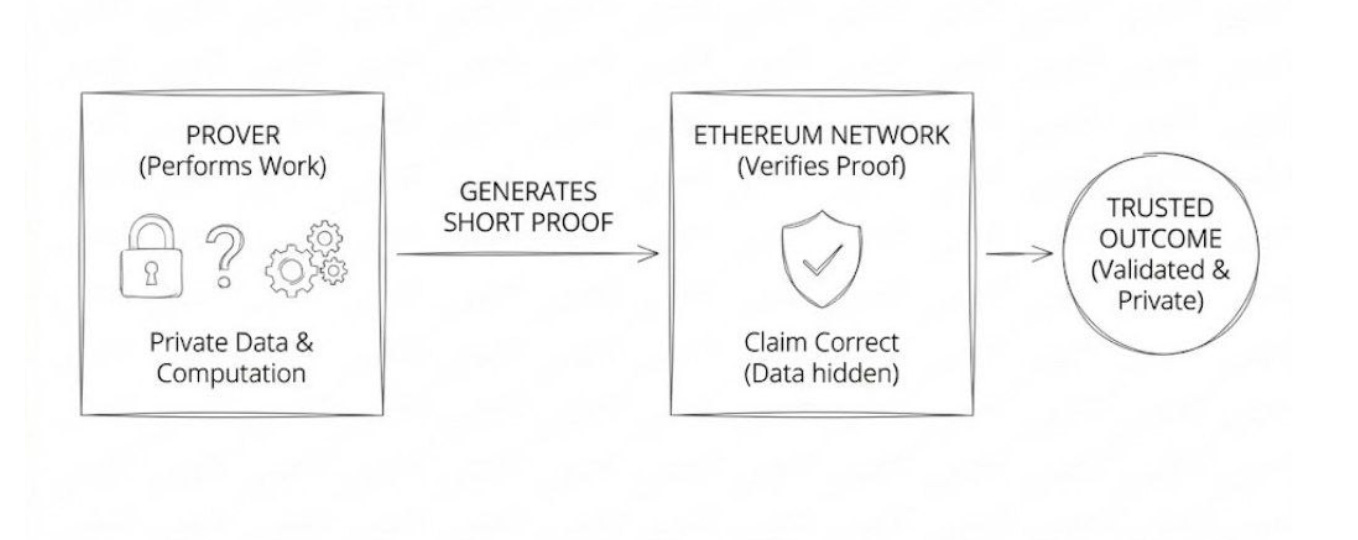
In 2018, the centre of gravity shifted from privacy to throughput. Ethereum’s scaling path made verification cheaper than re-execution for many workloads, and ZK became a means of compressing large amounts of computation into small proofs. That wave helped shape zk rollups and privacy systems by enabling succinct proofs of many state transitions, rather than forcing every validator to re-execute every step. As such, in rollups, execution happens offchain. A validity proof is posted onchain so that Ethereum can accept the new state without replaying each transaction.
We have protocols such as @aztecnetwork and general-purpose rollups like @zksync, @Starknet, and @Scroll_ZKP that are driving this development.
By the mid-2020s, ZK adoption shifted from single-purpose circuit dominance to a general-purpose proving infrastructure.
That is, we had zkVMs that can prove arbitrary programs, coprocessors that prove specific queries over onchain state, and proof networks that industrialise proving supply. These were developed by the teams from like Brevis, Axiom, Lagrange, Succinct, RISC Zero, and Cysic.
Today, ZK is less a single feature and more a utility layer for systems that need verifiable claims without leaking underlying data. We now have proof of personhood and membership, private group signalling and voting, and “prove an email”- style attestations that provide authentication to existing Web2 rails without revealing additional information.
Wallets use it for private membership and eligibility checks, prediction markets use it for hidden positions with provable settlement, and many other systems borrow it for one main thing: To make claims verifiable while keeping sensitive inputs private.
Worldcoin ID uses ZK proofs to ensure users can prove uniqueness without disclosing their identity, and it supports both offchain and onchain verification. On @SuiNetwork, a wallet can submit transactions using an OAuth login, with zkLogin, while preventing observers from linking the address to the OAuth identifier. An example is @surf_wallet, the best zklogin mobile wallet on Sui. Likewise, ZK Email uses proofs to verify signed email claims, such as DKIM-verified messages, without revealing the underlying email contents.
As @0xjyjonathan points out: “Zero-knowledge proofs are increasingly moving beyond academic theory. In Web2, they are already being used for privacy-preserving identity verification, such as proving age or eligibility without revealing personal data, as well as for data validation where specific conditions can be verified without exposing underlying datasets.
Within blockchain, ZK has traditionally been associated with scalability, such as ZK-based Layer 2s, and privacy-focused blockchains. ZK proofs offer an efficient way to compress and verify data, though they often come with higher upfront costs and greater implementation complexity compared to earlier scalability approaches like optimistic systems.
As time progresses, ZK proofs are likely to complement existing technologies. For example, ZK systems are being actively explored for trust-minimized bridge designs, including Bitcoin bridges that use optimistic SNARK-style constructions.”
This expansion of ZK from a privacy primitive into a general proving tool led to the stack splintering into specialised layers.
The map below is a glance at the current ZK stack:

The Cost Of Proving
In the past, it usually cost a lot, manually and financially, to verify anything on-chain. However, that cost has been shifted to Proving. Meaning, in exchange for that manual labour, they can simply verify those can verify those facts with ZK proofs. Therefore, proving is the new bill of verification, because the cost has been shifted to the proof layer.
Here’s how it goes:
A verifier runs a quick check,
Then the prover does the heavy computation,
The computation is turned into a proof, and
The cost is shifted onto hardware, energy, and latency.
Ethereum has made this tradeoff explicit. In July 2025, the Ethereum Foundation published a “real-time proving” target for an L1 zkEVM, aiming for proofs of at least 99% of mainnet blocks in under 10 seconds, on open source software, with on-premises hardware capped at around US$100,000 and 10 kW of power.
By December 2025, the Foundation reported major progress against that target, with proving latency dropping from about 16 minutes to 16 seconds, costs falling by 45x, and zkVMs proving 99% of blocks under 10 seconds on the target hardware profile.
The Cost Stack
Proofs are getting cheaper because several cost centres are falling at the same time, but at different speeds.
To get a grasp, we separate the stacks into three fees:
The verification bill: What it costs to verify a proof onchain.
The prover bill: What it costs to generate proofs, including hardware, energy, orchestration, and uptime.
The publishing bill: What it costs to post the data, and what the chain needs to accept the state transition.
The Verification Bill
On Ethereum, verifying a Groth16-style proof typically costs around 200,000 gas, and the cost increases with the number of public inputs. Ethereum reduced pairing precompile gas costs through EIP 1108, which is one reason modern onchain verification is viable at all.
Verification has a relatively fixed base cost. However, by aggregating multiple proofs into a single proof, the base verification cost can be amortised and spread across many users, reducing the chain’s exposure to expensive pairing costs.
The Prover Bill
Proving is a major operator cost curve, but it is not always the majority of total rollup cost from the user’s perspective. In many rollup designs, the dominant variable cost is data publication to L1 (calldata or blobs), while proving is a significant compute expense borne by the operator.
Which dominates depends on the rollup’s data model, traffic level, batching efficiency, and the proof system.
A practical way to think about rollup fees is: execution cost on L2, plus the cost of publishing data to L1, plus the operator’s proving overhead.
Even modest throughput can require heavy proving hardware, because proving is compute-intensive even when the transaction count is not huge. For example, zkSync publishes minimum hardware targets for certain prover configurations, and RISC Zero has published a reference path for pushing proof times down using a larger GPU setup.
The Publishing Bill
Proofs do not remove the need to publish what the chain needs. Rollups still pay to publish data, whether as calldata, blobs, or alternative availability commitments, depending on how the system is built.
In practice, this means proving costs can fall fast while total user fees do not fall as much, if data publication remains the dominant cost. This happens because the proving cost and publishing cost move on different rails. Proving benefits from software optimisations and hardware progress, while Publishing is constrained by L1 data pricing (calldata or blob fees). So proving can get cheaper while fees remain sticky if L1 data remains the binding cost.
As a consequence, user fees are a mix of proving cost and data cost. Proving has been falling quickly, but data publication is often the larger line item, especially during periods of high demand for blockspace. This is why proofs can become cheap while users still feel fees, and the proof bill can also shrink while the data bill stays stubborn. When evaluating whether ZK is getting cheaper for users, the right question is not only how cheap proofs are, but also whether the total fee is now dominated by data publication.
So when people talk about ZK “getting cheaper,” they usually mean some mix of these 3 numbers moving down:
Lower fees per proof check
Lower cost to generate proofs
Lower cost to publish what Ethereum needs
What Makes Proving Cheaper?
If proofs are expensive, rollups subsidise users and bleed on ops, and when they are cheap, fees can fall without collapsing margins. This section explains where proving costs come from, how teams measure progress, and why the fastest improvements do not always translate 1-to-1 into lower user fees. The goal is to connect the benchmarks to real unit economics.
When examining the open benchmarking, the frontier is shifting across teams and hardware is discovered, telling you whether proving is moving from “specialised lab work” toward ‘commodity infra.
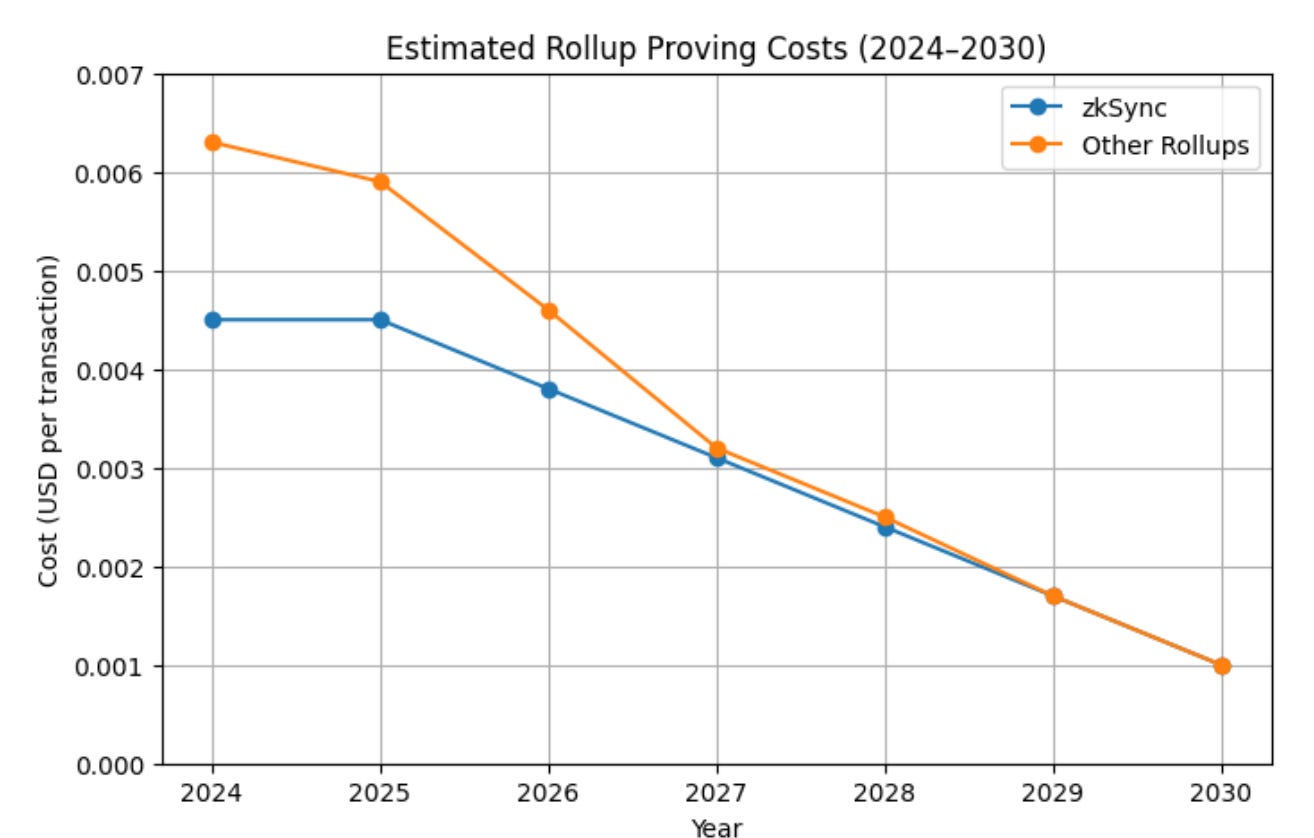
Ethproofs tracks proof latency and cost estimates across zkVMs and prover setups.
They estimate the amount of GPU work required by a proof and the corresponding dollar cost, using a hardware price index, a method for comparing the efficiency of proving over time.
Ethproofs site-wide snapshot:

zkVMs and zkEVMS
zkVMs make arbitrary programs provable, which is why they are at the core of the ‘validate instead of execute’ direction for Ethereum.
Vitalik Buterin recently noted that zkEVMs have reached an alpha stage, meaning performance is already at production-quality levels and the main remaining work is on safety. He mentioned this, alongside PeerDAS on mainnet, as part of a shift toward Ethereum supporting decentralised consensus with much higher bandwidth over the next few years. This is why zkVMs’ progress is increasingly about reliability and actual deployments, rather than only faster proving.
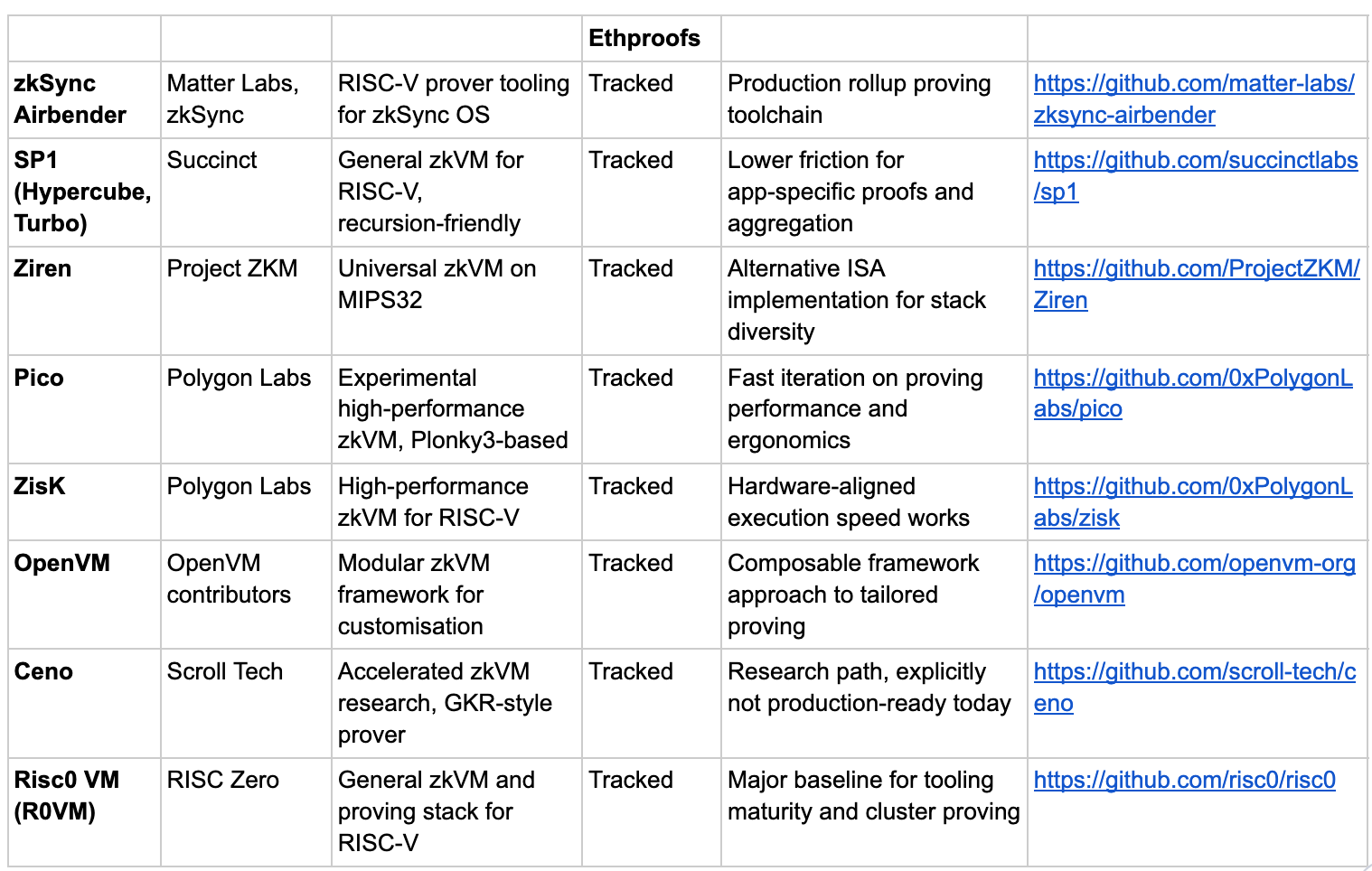
A practical way to track the proving layer is to watch which zkVMs are actively shipping, what they optimise for, and how their proving stacks evolve. The table below uses Ethproofs’ tracked zkVM list as a baseline and explains why it matters.
What to watch in ZK through 2026?
Progress is easiest to track when metrics are hard to game. Interesting developments to have a look at are:
The median and tail proving latency for Ethereum-sized workloads.
The cost per proven block under a clear cost model, plus the hardware assumptions behind it.
The share of proving capacity that can be run outside a single vendor or a single data centre class hardware.
The number of production systems that rely on zkVMs for more than marketing, including coprocessors and bridges.
Privacy adoption is measured as actual private user actions, and not just protocol launches.
The fee is split between proving and data publication, because proving can get cheap while users still pay for data.
Proofs are becoming cheap enough to use as a default tool.
They are no longer a special feature reserved for users with a budget. When proving costs collapse, teams can prove more often, ship more proof-driven products, and rely on zkVMs and coprocessors for the real workloads. That is why ZK is showing up in more places, rollups, wallets, eligibility checks, verifiable cross-chain logic, and applications that need to prove something without exposing inputs.
Vitalik Buterin’s roadmap outlines what this should look like next:
Early zkEVM node usage and broader scaling steps in 2026
Deeper safety and structural changes through 2026 to 2028
A path in which zkEVMs become the primary way blocks are validated later in the decade.
The next phase is operational. It is about how easy provers are to run reliably, how widely proving supply decentralises, and whether pricing continues to converge toward commodity compute as more applications and networks depend on proofs.
written by @RubiksWeb3 ✍️
Every week for the last 3 years, we have shared our research for free, directly in your email. Not a subscriber yet? Let’s fix it:

If you are more of a Telegram guy, you can read all of our research without the noise on our TG channel: